Comparando medidas de estatística descritiva em Python e R
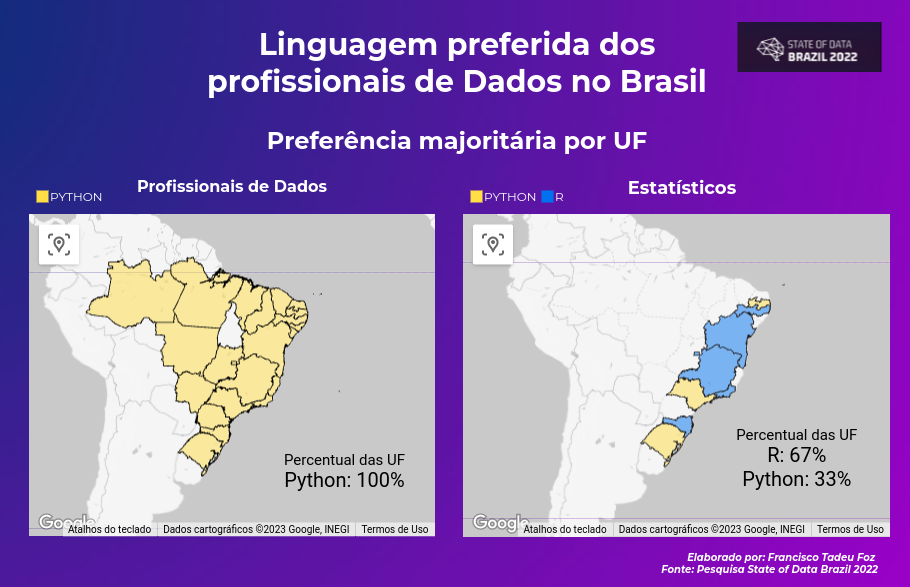
A discussão entre Python e R dentro da área de dados, talvez esteja no final. Atualmente, Python é a linguagem preferida entre todos os profissionais de dados no Brasil.
De acordo com a pesquisa State of Data Brasil 2022, realizada pela comunidade do Data Hackers e a Bain & Company, a linguagem preferida entre todas as UF e todos os profissionais de dados (em sua maioria) é o Python.
Apenas entre as pessoas estatísticas que a conta vira e R sai na frente (com 67% das UF).
“R vai morrer, ninguém mais vai usar!”
Bom, as coisas não são bem assim. Particularmente, eu também tenho preferência por Python, mas se tem algo que aprendi em tecnologia é: não vire refém de ferramentas.
“Problemas de negócios são agnósticos em relação às ferramentas.”
Por este motivo, tenho lido e estudado sobre estatística e decidi rever alguns conceitos, comparando Python e R, e assim, ter outras perspectivas por ferramentas diferentes.
No texto de hoje irei trazer algumas medidas de estatística descritiva, a partir do conjunto de dados da teses e dissertações sobre Inteligência Artificial depositadas na BDTD.
Bora lá?!
Sumário
Tabelas de frequência
Tabelas de frequência é uma das mais básicas e úteis formas, para se explorar dados e entendê-los.
Em Python, utilizando Pandas, podemos usar um .value_counts() em uma Series e ele irá contar os valores. Posso simplesmente também passar um .value_counts(normalize=True) e desse forma já ter o percentual.
Fiz uma função, pois iria utilizar muito depois:
def tabela_frequencia(df,variavel):
'''
Esta função irá realizar uma tabela de frequência de acordo com a
variavel inserida do conjunto de dados.
df = Conjunto de dados
variavel = Variável do conjunto de dados da armazenadas na BDTD
'''
frequencia = df[variavel].value_counts()
percentual = df[variavel].value_counts(normalize=True).round(4)*100
tabela_freq = pd.DataFrame({'Frequência':frequencia,
'Percentual(%)':percentual})
return tabela_freqCom isso sei que as instituições que mais publicaram trabalhos sobre foram a UNICAMP, UFSC, UFRGS, ITA e UFPE.

Em R, já usaria a função table() para contar os valores e a prop.table() para contar os valores percentuais.
Também precisei usar a arrange da biblioteca Dplyr para deixar os valores ordenados do maior para o menor.
tabela_frequencia <- function(df, variavel) {
# Esta função irá realizar uma tabela de frequência de acordo com a
# variavel inserida do conjunto de dados
# df = Conjunto de dados
# variavel = Variável do conjunto de dados da armazenadas na BDTD
# Calcula a frequência e percentual da variável
frequencia <- table(df[[variavel]])
percentual <- round(prop.table(frequencia) * 100, 2)
# Cria um dataframe com os resultados
tabela_freq <- data.frame(cbind('Frequência' = frequencia,
'Percentual'= percentual))
tabela_freq <- arrange(tabela_freq,desc(Percentual))
return(tabela_freq)O resultado é o mesmo, apenas com as diferenças das estruturas de cada linguagem.

Medidas de tendência central
As medidas estatísticas que provavelmente grande parte das pessoas conhecem: média, mediana e moda.
Vou extrair as medidas a partir da frequência de trabalhos publicados por ano:

MÉDIA
Em Python, utilizamos o .mean() para poder extrair a média aritmética de uma Series, utilizando Pandas.
freq_ano['Frequência'].mean()Em R, utilizamos a função mean() em um vetor para extrair a média.
freq_ano$Frequência %>% mean()Usei o pipe %>% apenas porque gosto de deixar mais claro as operações com as funções, mas se fizesse mean(freq_ano$Frequência) seria igual.
Se você quiser saber mais sobre o pipe, veja esse capítulo do curso R:
MEDIANA
Em Python, utilizamos o .median() para poder extrair a mediana aritmética de uma Series, utilizando Pandas.
freq_ano['Frequência'].median()Em R, também é igual e utilizamos a função median() em um vetor para extrair a mediana.
freq_ano$Frequência %>% mean()MODA
Em Python, utilizo o .mode() para poder extrair a moda de uma Series, utilizando Pandas.
freq_ano['Frequência'].mode()Posso passar um [0], para pegar apenas o valor int e não uma Series.
freq_ano['Frequência'].median()[0]Em, R não temos uma função que possa diretamente pegar a moda. Existe a mode() no Desctools, mas se ela houver mais do que uma, ela retornará apenas a primeira.
Para isso, faço uma função que conte os valores, depois filtre a partir dos valores máximos que tenho dela:
Moda <- function(x){
tabela <- table(x)
moda <- as.numeric(names(tabela)[tabela == max(tabela)])
return(moda)
}
freq_ano$Frequência %>% Moda()Com isso consigo obter a moda.
Medidas de separatrizes
Medidas de separatrizes são muito importantes para entendermos os limites da distribuição dos dados.
Tanto em R quanto Python, utilizamos a função quantile() para dividir de acordo com o percentual necessário.
QUARTIS
Em Python, podemos usar o .quantile() e passar os percentuais que quero dividir.
Por exemplo:
freq_ano['Frequência'].quantile([0.25,0.5,0.75])
Assim, dividirá em 25%, 50% e 75% dos dados.
Em R, também usamos a função quantile():
quantile(freq_ano$Frequência, c(0.25,0.5,0.75))DECIS
Em Python, para os decis, podemos fazer um for para não ficar tendo que escrever todos os percentuais:
freq_ano['Frequência'].quantile([i/10 for i in range(0,11)])Em R, podemos usar a função seq() para poder limitar o intervalos dos valores:
quantile(freq_ano$Frequência, seq(0.1, 0.9, 0.1))A função seq() irá colocar um valor inicial, um final e um “passo” gerando um vetor para a quantile separar.
CENTIS
A lógica é a mesma para as duas linguagens, apenas modificamos a grandeza dos números.
Python:
freq_ano['Frequência'].quantile([i/100 for i in range(0,101)])R:
quantile(freq_ano$Frequência, seq(0.01, 0.99, 0.01))Medidas de dispersão
Medidas de dispersão são importantes para entendermos como nossos dados estão distribuídos em relação a uma medida de tendência central.
DESVIO MÉDIO ABSOLUTO
Em Python, utilizamos a função .mad() para se obter o desvio médio absoluto em uma Series, usando o Pandas.
tabela_frequencia(bdtd_IA,'publicationDates')[['Frequência']].mad()Em R, usamos a função MeanAD() da biblioteca Desctools para se obter o desvio médio absoluto.
tabela_frequencia(bdtd_IA,'publicationDates')$Frequência %>% MeanAD()VARIÂNCIA
Em Python, utilizamos a função .var() para obter a variância de uma Series, usando o Pandas.
tabela_frequencia(bdtd_IA,'publicationDates')[['Frequência']].var()Em R, também utilizamos uma função var():
tabela_frequencia(bdtd_IA,'publicationDates')$Frequência %>% var()DESVIO PADRÃO
Em Python, utilizamos a função std() para se obter o desvio padrão de uma Series, utilizando o Pandas.
tabela_frequencia(bdtd_IA,'publicationDates')[['Frequência']].std()Em R, utilizamos a função sd() para se obter o desvio padrão de um vetor.
tabela_frequencia(bdtd_IA,'publicationDates')$Frequência %>% sd()OUTRAS FUNÇÕES:
A função de “resumo estatístico” básico do Python Pandas é .describe() , que é mais completo que o summary() do R, pois tem a contagem de valores e o desvio padrão além das medidas de separatrizes e médias.


Visualizações, principalmente boxplots e histogramas, são basicamente iguais nas duas.
Em Python, utilizamos do matplotlib e seaborn para auxiliar na plotagem:
freq_instituicao_ano = bdtd_IA[['institutions','publicationDates']].value_counts().to_frame('frequencia').reset_index()
instituicoes_mais_freq = ['UNICAMP','UFSC','UFRGS','ITA','UFPE']
freq_instituicoes_mais_freq_ano = freq_instituicao_ano.query('institutions == @instituicoes_mais_freq')
ax = sns.boxplot(x='institutions',y='frequencia',data=freq_instituicoes_mais_freq_ano)
ax.set_title('Variação de trabalhos publicados por ano por instituição',size=20)
ax = ax
E em R, utilizamos o ggplot2 para criar o gráfico:
freq_instituicao_ano <- bdtd_IA %>%
count(institutions, publicationDates) %>%
rename(frequencia = n) %>%
select(institutions, publicationDates, frequencia)
instituicoes_mais_freq <- c("UNICAMP", "UFSC", "UFRGS", "ITA", "UFPE")
freq_instituicoes_mais_freq_ano <- freq_instituicao_ano %>%
filter(institutions %in% instituicoes_mais_freq)
# Plotar o boxplot
ggplot(freq_instituicoes_mais_freq_ano,
aes(x = institutions, y = frequencia,fill=institutions)) +
stat_boxplot(geom = 'errorbar', width = 0.4) +
geom_boxplot() +
ggtitle('Variação de trabalhos publicados por ano por instituição')
Considerações finais
Python ou R?
Bom, eu ainda continuo a preferir Python, principalmente por conta da sintaxe e das operações de manipulação e transformação de dados.
Python realmente é mais fluido de se escrever código.
Mas eu estava estudando estatística então não importava muito mesmo a ferramenta.
Aliás, fica a dica para você onde estudar:
Lá tem cursos de estatística com Python e também com R.
Caso você não seja aluna(o) ainda, confira meu cupom de desconto especial aqui.
Além disso, linguagem é ferramenta e ferramenta depende do problema e de gosto, portanto não defenda que uma seja melhor que a outra.
Falei de Python e R, também tem o SQL…
Que é a linguagem mais utilizada pelos profissionais Analistas de Dados, no qual descobri a partir dessa pesquisa:
E também já ouvi falar de Julia, principalmente para projetos maiores de machine learning, mas nunca dei um Hello World.
E você?!
Qual é a sua linguagem de programação preferida?
Se você chegou até aqui e curtiu, dê palmas, compartilhe e se inscreva para me acompanhar.
Ainda há muito a se explorar.